















 548-549 / 568
548-549 / 568

Improved Automatic speech recognition
Shani Mualem
Advisor: Eran Aharonson
Medical Engineering
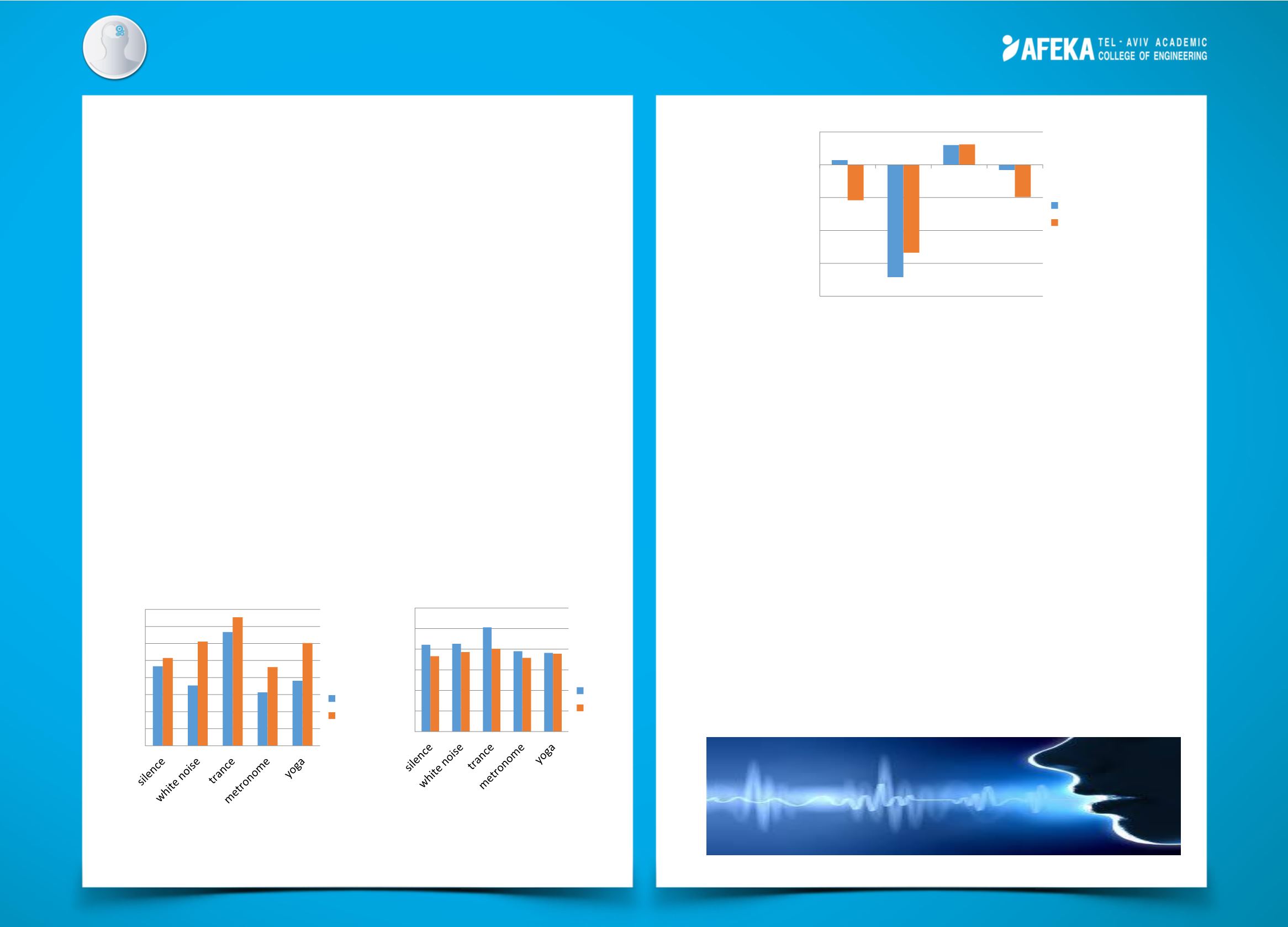
Figure 3- Speaker’s SNR improvement
4. discussion
Female and male showed highest speech db while playing trance music
on background. This result was expected due to Lombard effect.
According to Lombard effect, speaking rate may be reduced at noisy
environment. Therefore, in figure2 we can see that time per word in
trance music (for male and female speakers) was the highest.
The lowest speech db was in metronome condition. by the literature
review, there are explanations about this results for stutterers speakers
and we can infer that there is possibility that the same reason also for
non-stutterers speakers - metronome diverts the stutterers speakers
attention away from the sound of his own voice, produces a general
increasing in the speed of speaking.
Figure 3 shows that despite the separately charts between genders, the
outcomes were similar- we received the highest SNR in metronome and
the lowest in trance music. It can be conclude that the speech signal in
metronome improved above 30% from the original signal without noise
background. On the other hand, we got the lowest ratio in trance music-
as was expected that we get low SNR due to Lombard effect.
Another variable that was investigated is the frequency of speech signal
in each of the background noise. There are no significant changes
between the noises, therefore it cannot be determent high or low speech
recognition by the frequencies of speech signal
1. Background
Automatic speech recognition (ASR) is the process of converting spoken
words into text.
The main idea is to create for the user artificial noisy environment (such as
playing in earphones) that causes the user to alter their speech in order to
enhance intangibility and therefore enhance the ASR performance.
2. Objective
In this research we enhance ASR performance by using Lombard effect - a
phenomenon in which speakers alter their vocal production in noisy
environments, such as loud parties or restaurants, in order to enhance
comprehensibility.
Therefore we improve:
• SNR- Signal to Ratio – the user speaks louder.
• Speech rate – the user speaks slower
3. Method
By using Matlab algorith, and Praat (speech processing software) we
compare the speech power and rate, and calculate the speech SNR and
rate between different virtual environment of "noise"- white noise,
metronome, and different kinds of music ( trance, yoga's music) and silent.
3. Results
We tested XX speakers (XX male and YY female) each wearing
earphones (virtual noise source). The users read a pre-defined text – the
text was recorded and we measured both the power and rate of speech
Figure 1- Speech DB
Figure 2- Speech rate
0
0.05
0.1
0.15
0.2
0.25
0.3
Time per word [sec]
female
male
71
72
73
74
75
76
77
78
79
dB
female
male
-2
-1.5
-1
-0.5
0
0.5
white noise trance metronome yoga
SNR
female
male